Imitation Learning for Structured Prediction and Automated Fact Checking
Andreas Vlachos
a.vlachos@sheffield.ac.uk
University of Sheffield
Why Natural Language Processing?
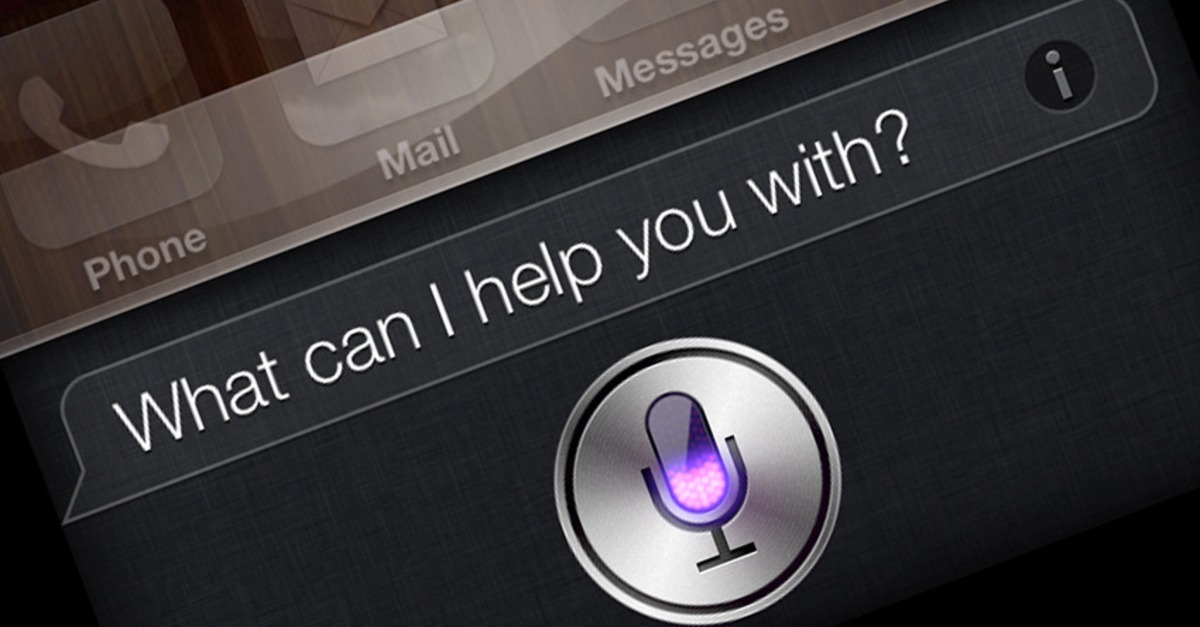




Why ML for NLP?

Part 1: Imitation learning for structured prediction in natural language processing
Joint work with:
- Gerasimos Lampouras (UCL, Sheffield)
- Sebastian Riedel, Jason Naradowsky, James Goodman (UCL)
- Daniel Beck, Isabelle Augenstein (Sheffield)
- Stephen Clark (Cambridge)
- Mark Craven (Wisconsin-Madison)
Structured prediction in NLP
- part of speech (PoS) tagging
- named entity recognition (NER)
Input: a sentence $\mathbf{x}=[x_1...x_N]$
Output: a sequence of labels $\mathbf{y}=[y_{1}\ldots y_{N}] \in {\cal Y}^N$
More Structured Prediction

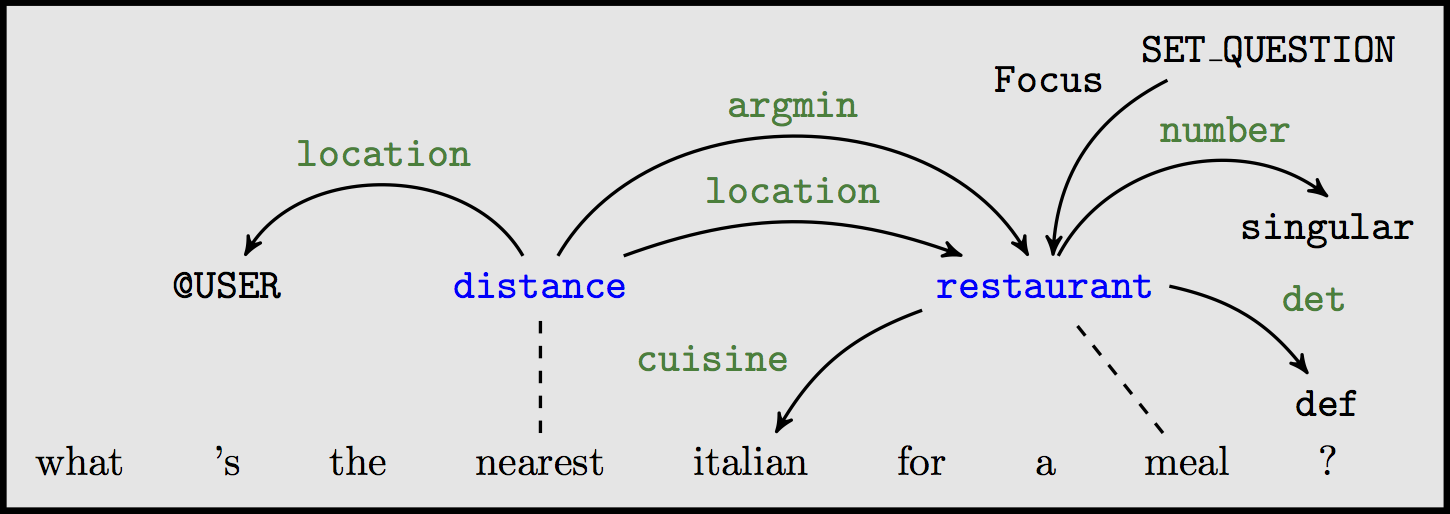
- syntactic parsing
- semantic parsing, question answering, etc.
Input: a sentence $\mathbf{x}=[x_1...x_N]$
Output: a graph $\mathbf{G}=(V,E) \in {\cal G_{\mathbf{x}}}$
Even More Structured Prediction

Natural language generation (NLG), but also summarization, decoding in machine translation, etc.
Input: a meaning representation/database record
Output: $\mathbf{w}=[w_1...w_N], w\in {\cal V}\cup END$
Imitation Learning for Structured Prediction
We assume gold standard
output for supervised training

But we train a classifier to predict
actions constructing the output.
Actions not in gold;
IL is rather semi-supervised
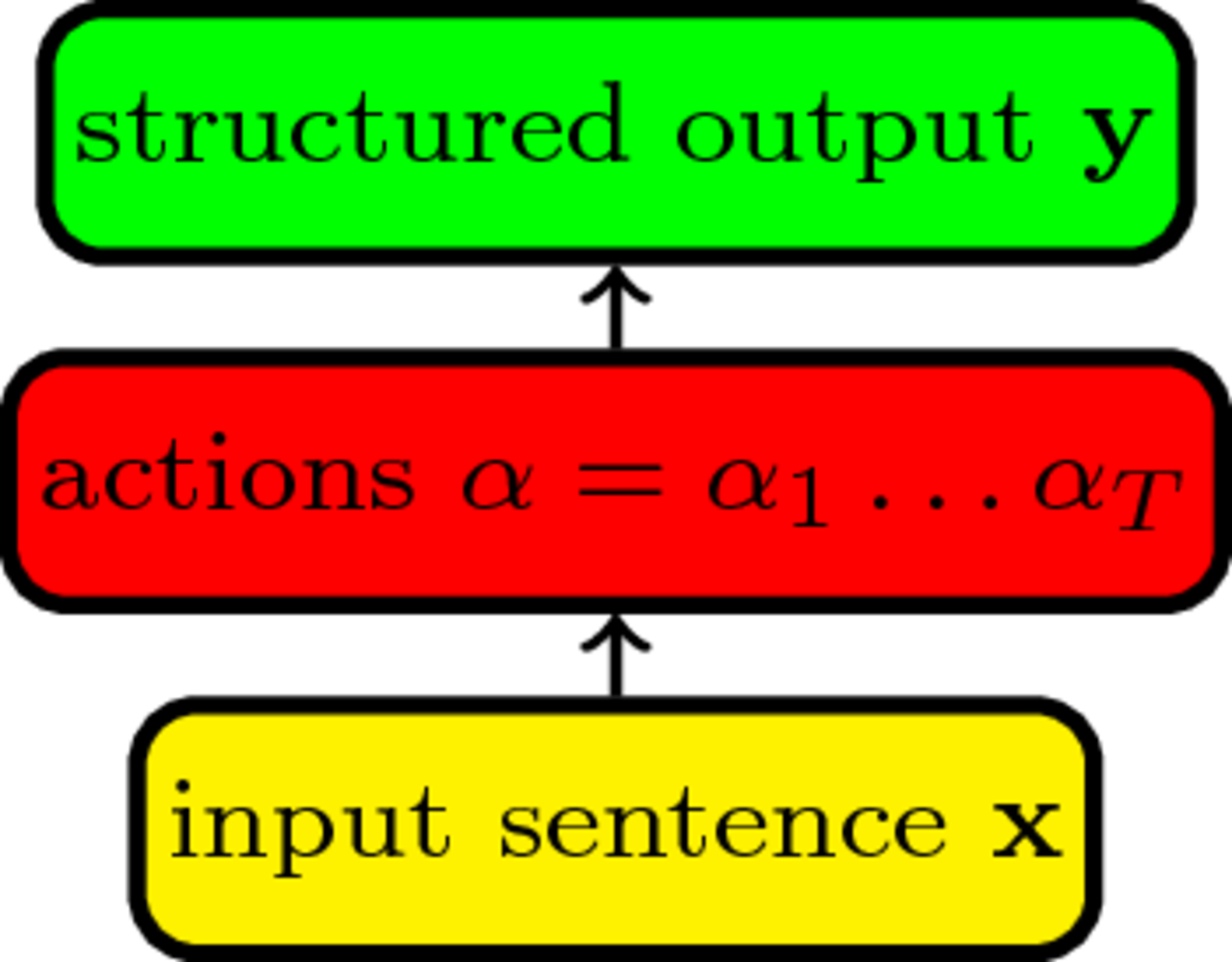
Incremental structured prediction
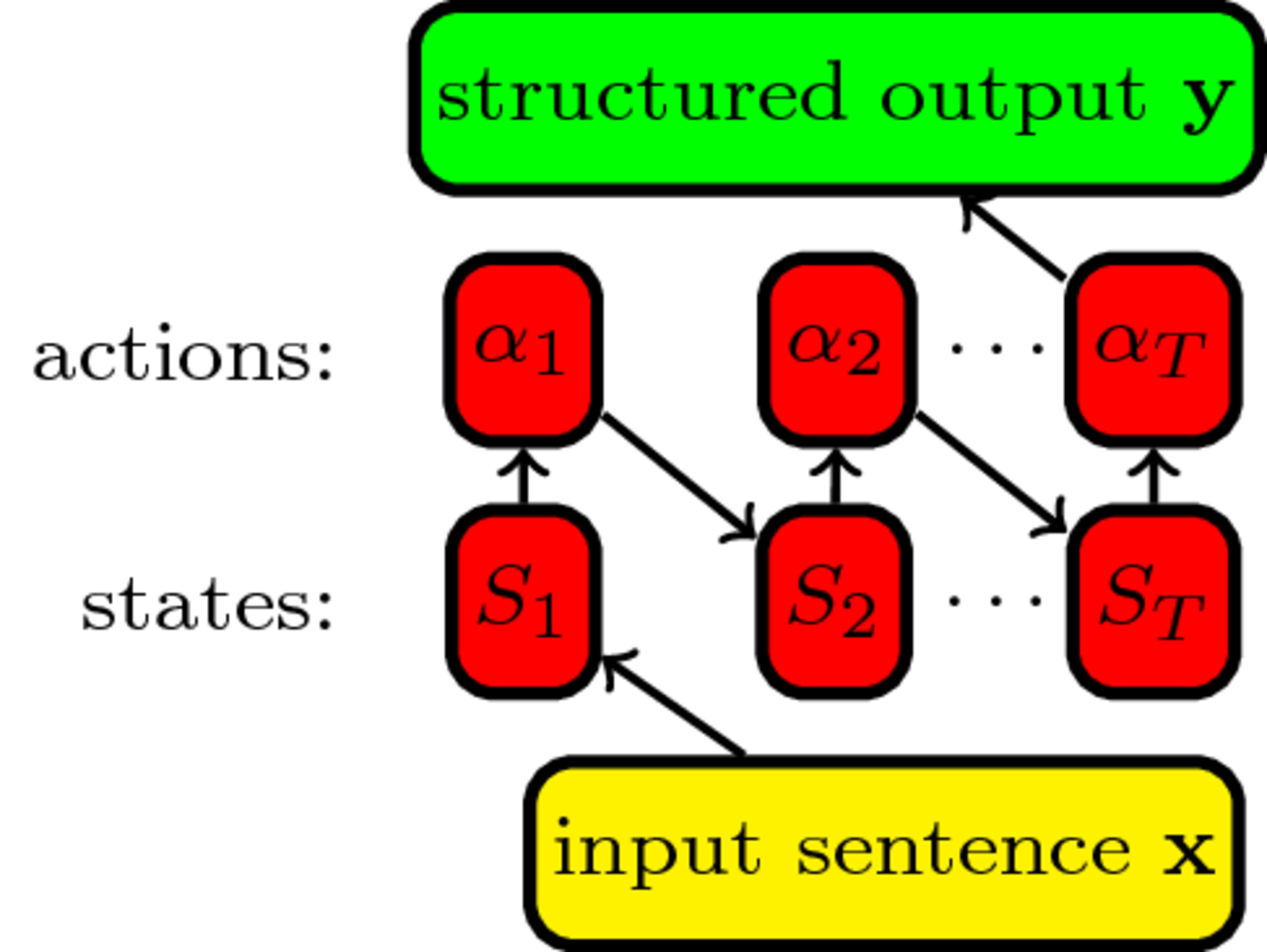
Breaking structured prediction into actions
Incremental structured prediction
A classifier predicting a label at a time given the previous ones: \begin{align} \hat y_1 &=\mathop{\arg \max}_{y \in {\cal Y}} f(y, \mathbf{x}),\\ \mathbf{\hat y} = \quad \hat y_2 &=\mathop{\arg \max}_{y \in {\cal Y}} f(y, \mathbf{x}, \hat y_1), \cdots\\ \hat y_N &=\mathop{\arg \max}_{y \in {\cal Y}} f(y, \mathbf{x}, \hat y_{1} \ldots \hat y_{N-1}) \end{align}- use our favourite classifier
- no restrictions on features
- prone to error propagation (i.i.d. assumption broken)
- local model not trained wrt the task-level loss
Imitation learning for Part of Speech tagging
Gold standard
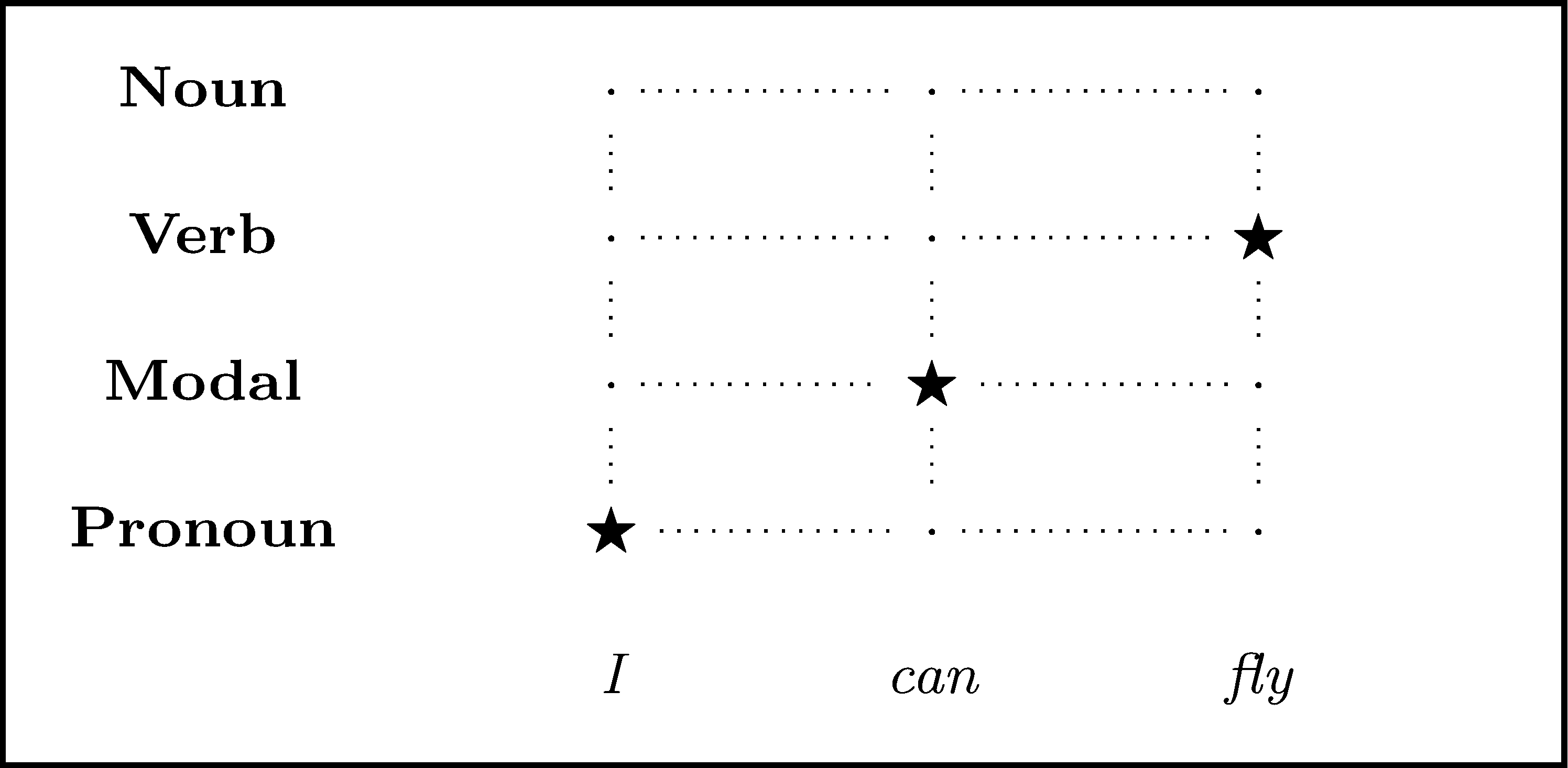
expert policy: at each word return the correct PoS tag
Imitation learning for Part of Speech tagging
Standard training (exact imitation of the expert)
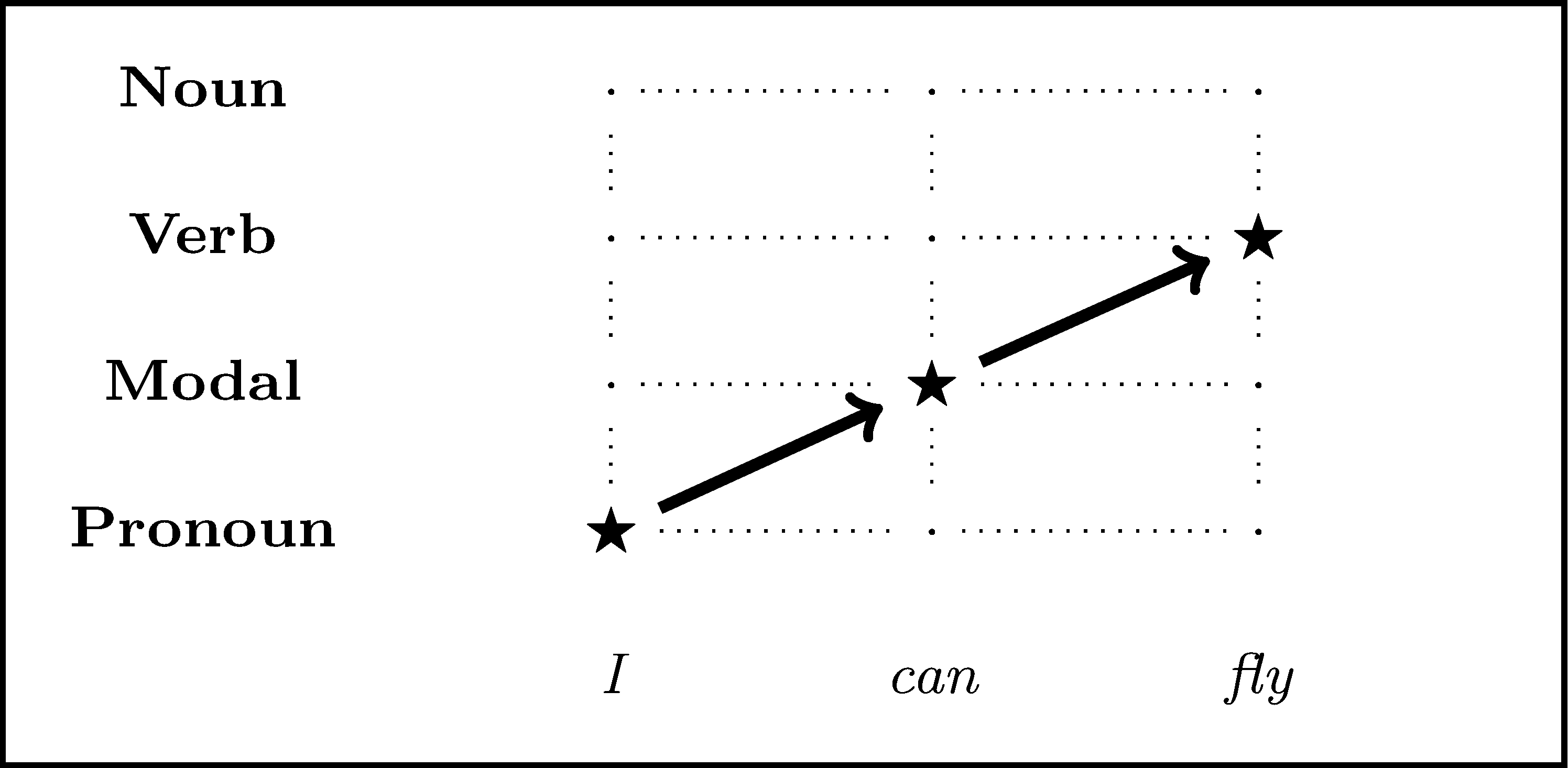
| word | label | features |
|---|---|---|
| I | Pronoun | token=I, prev=NULL... |
| can | Modal | token=can, prev=Pronoun... |
| fly | Verb | token=fly, prev=Modal... |
Imitation learning for Part of Speech tagging
Labels as costs
| word | Pronoun | Modal | Verb | Noun | features |
|---|---|---|---|---|---|
| I | 0 | 1 | 1 | 1 | token=I, prev=NULL... |
| can | 1 | 0 | 1 | 1 | token=can, prev=Pronoun... |
| fly | 1 | 1 | 0 | 1 | token=fly, prev=Modal... |
Imitation learning for Part of Speech tagging
Breaking down action costing
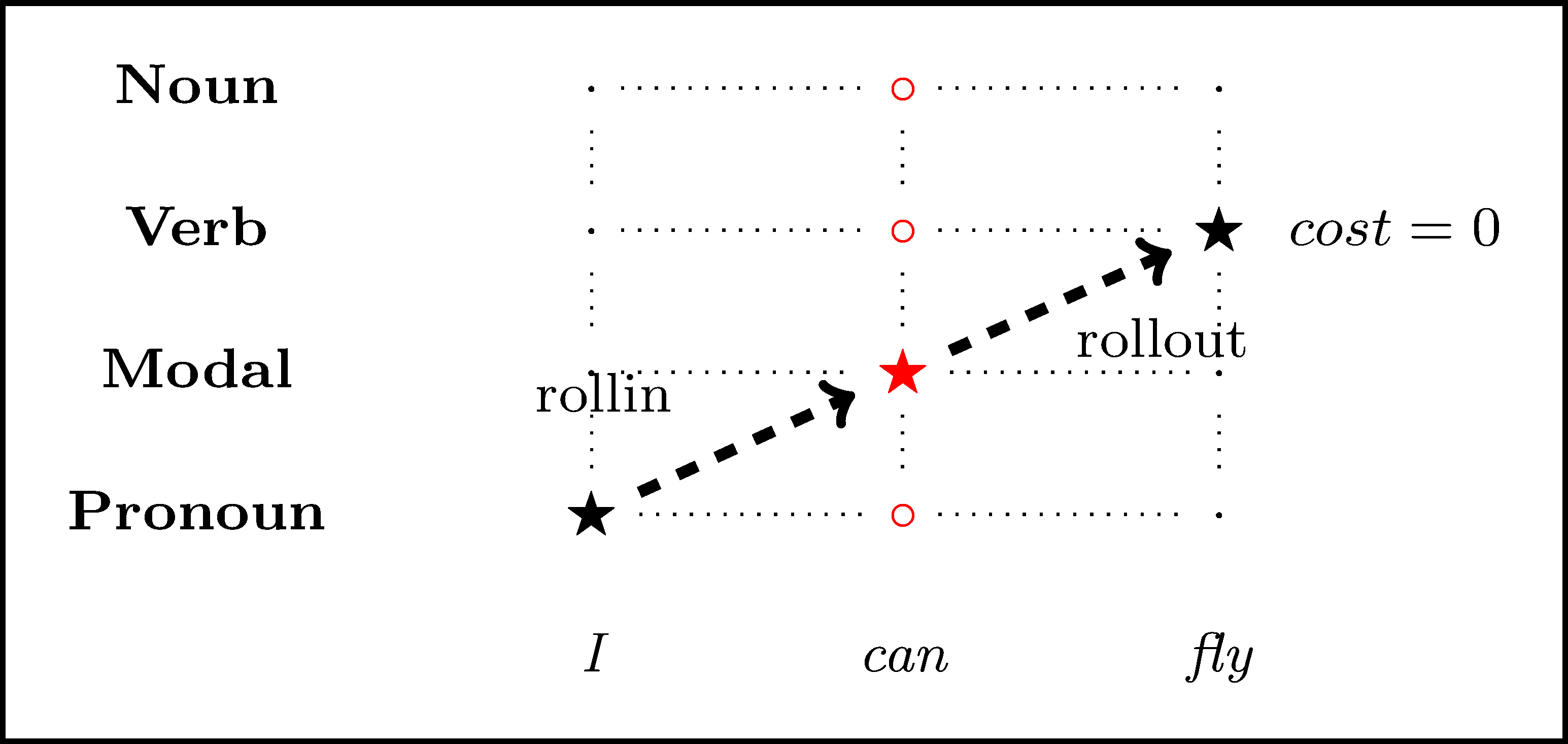
- rollin to get a trajectory through the sentence
- for each possible label:
- rollout till the end
- cost the complete output with the task loss
- construct a training instance
Imitation learning for Part of Speech tagging
Breaking down action costing
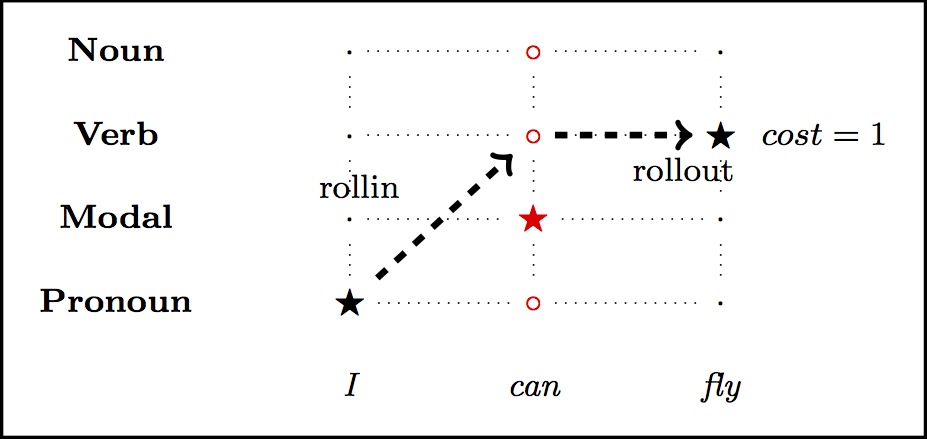
- rollin to get a trajectory through the sentence
- for each possible label:
- rollout till the end
- cost the complete output with the task loss
- construct a training instance
Imitation learning for Part of Speech tagging
Breaking down action costing
- rollin and rollout follow the expert policy
- loss is the number of incorrect tags
- correct label has 0 cost, the rest 1
| word | Pronoun | Modal | Verb | Noun | features |
|---|---|---|---|---|---|
| can | 1 | 0 | 1 | 1 | token=can, prev=Pronoun... |
Imitation learning for Part of Speech tagging
Mix (i.e. roll a dice) the expert policy with the previously learned classifier during rollin and rollout
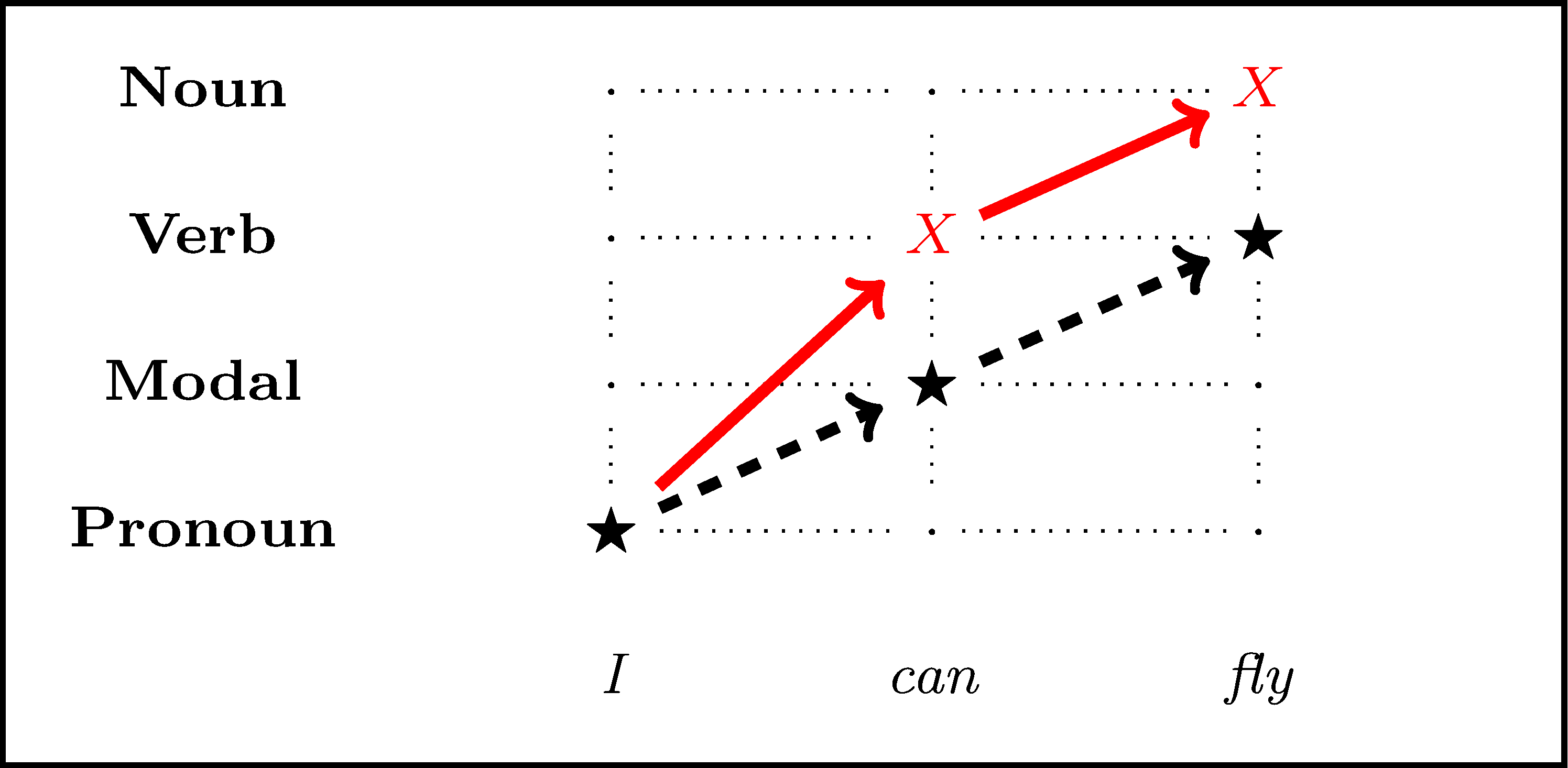
| word | Pronoun | Modal | Verb | Noun | features |
|---|---|---|---|---|---|
| can | 1 | 0 | 2 | 1 | token=can, prev=Pronoun... |
| fly | 1 | 1 | 0 | 1 | token=fly, prev=Verb... |
Is it reinforcement learning?
Yes (a kind of): we train a policy to
maximize rewards/minimize losses

But learning is facilitated by an expert

What about Recurrent Neural Networks?
They also predict a sequence of actions incrementally:
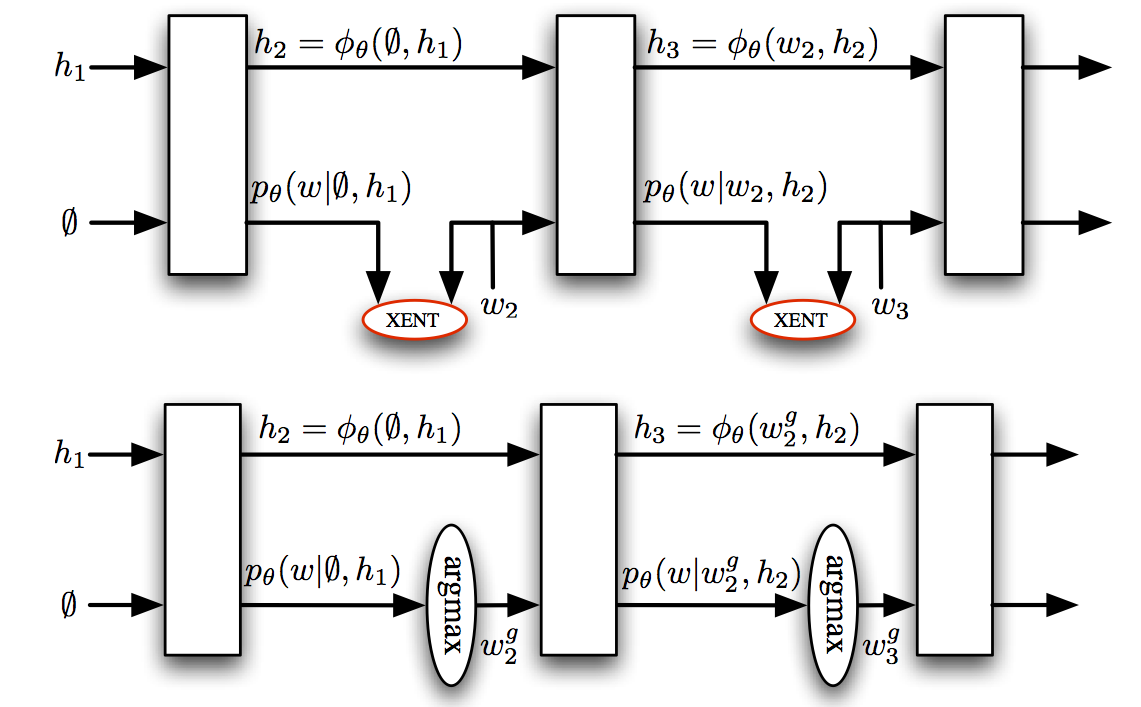
and face similar problems (Ranzato et al., 2016):
- trained at the word rather than sentence level
- assume previous predictions are correct
Abstract meaning representation parsing
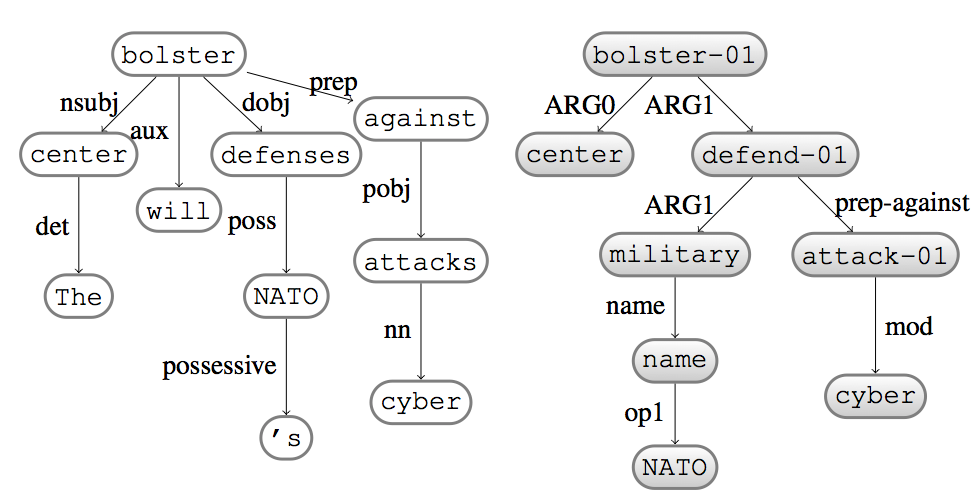
- Designed for semantics-based MT
- Many applications: summarization, generation, etc.
- Long, complex (>100 steps, 10^4 labels) action sequences
Comparison on AMR rel pre1.0
- Best results to date (Goodman et al., ACL 2016)
- No external resources used
Natural Language Generation (NLG)
- Reversed semantic parsing, similar to translation
- Unlike MT, labeled data is rather limited
- Evaluation with BLEU
Human evaluation
- SOTA on three tests (Lampouras and Vlachos 2016)
- No rules, re-ranking or templates, just two classifiers
Part 2: Automated fact checking
Joint work with:
- James Thorne (Sheffield)
- Dhruv Ghulati, Rob Stojnic (Factmata)
- Christos Christodoulopoulos, Arpit Mittal (Amazon)
- Sebastian Riedel, Will Ferreira (UCL)
Fact checking simple numerical statements
 Vlachos and Riedel (EMNLP 2015)
Vlachos and Riedel (EMNLP 2015)
Knowledge base population evaluation
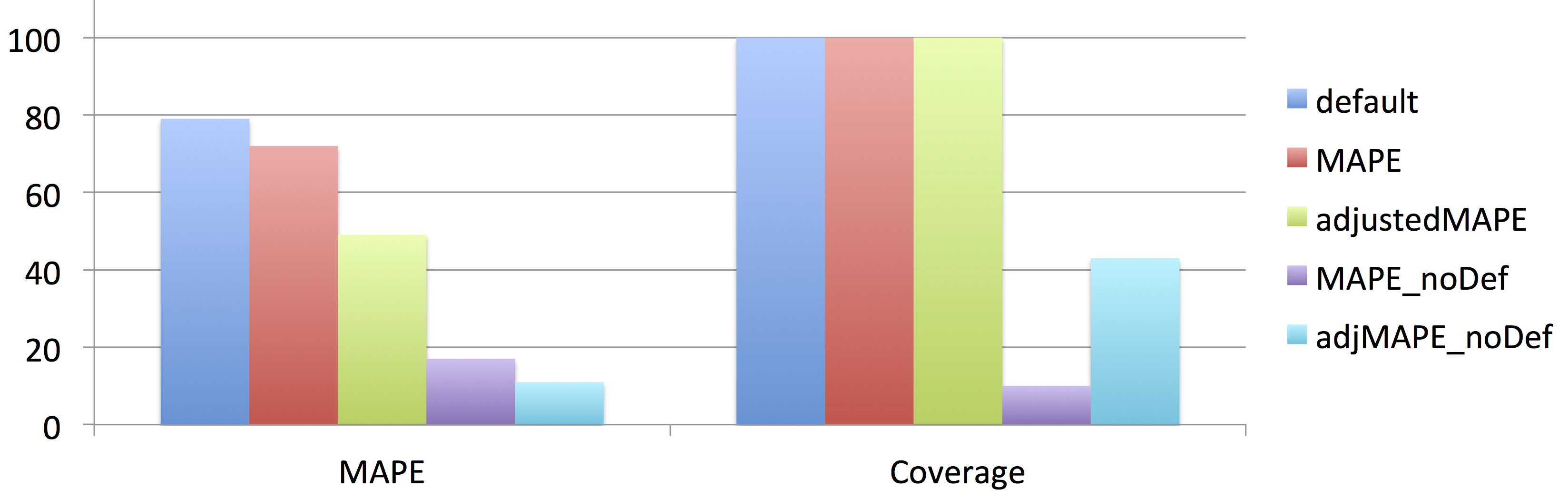 lower MAPE and higher Coverage are better
lower MAPE and higher Coverage are better
Factmata

with Dhruv Ghulati and Sebastian Riedel
Emergent.info automation
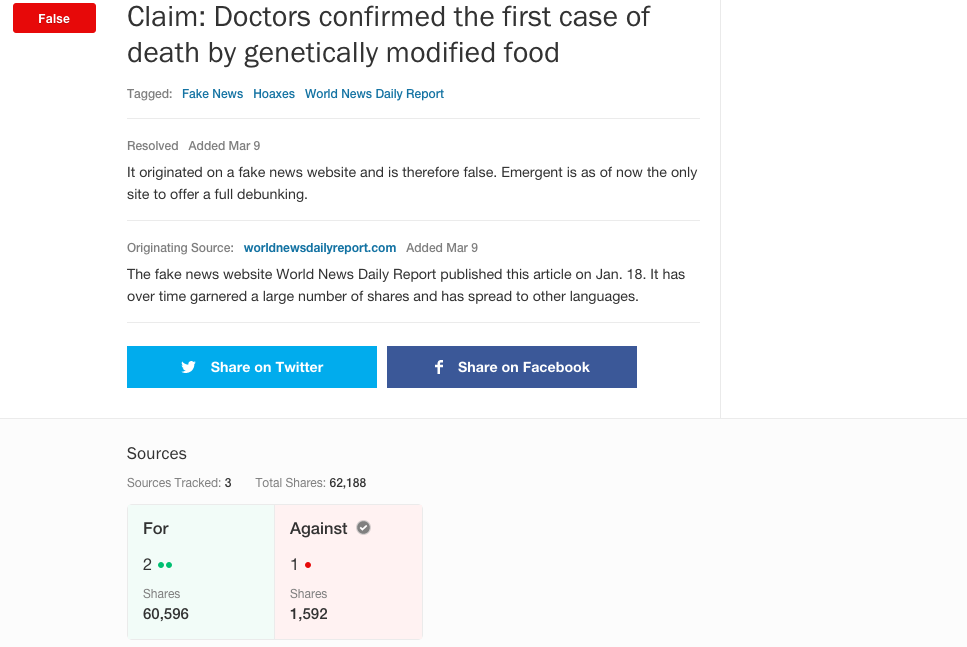
Emergent.info automation

Three way classification: a headline can be for, against or observing a claim
Developed a classifier with manually engineered features achieving 73% accuracy, 26% higher than a mature textual entailment system
The Fake news challenge

Our paper evolved into the Fake News Challenge:
- Extending to comparing claims with full articles
- Extra class unrelated: the article discusses a different topic
- 50 participating teams, max 82% weighted accuracy
FEVER example

Shared task being planned for 2018